Tags: stats, language, weird_questions 2nd Feb 2023
Acronymic Groups (Part one)
The other day I was watching a round from the British gameshow “Would I Lie To You?” where Lee Mack claimed he remembers his exes’ names by the acronym BERMUDA. A video clip of the round is available here.
It made me wonder about the actual probability of this scenario, and about the general case of being able to form an acronym from the names of your exes-or any group of people. This post covers the exact scenarios Lee Mack describes; a follow-up will cover the general case.
I’ll define an acronymic group as a collection of individuals whose names, when considering the initial letters, can be arranged to form a word.
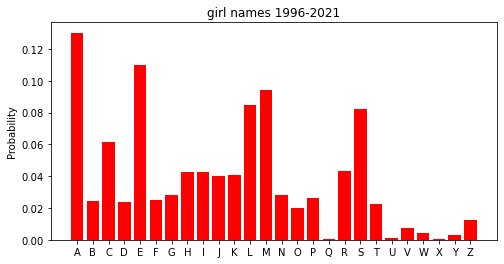
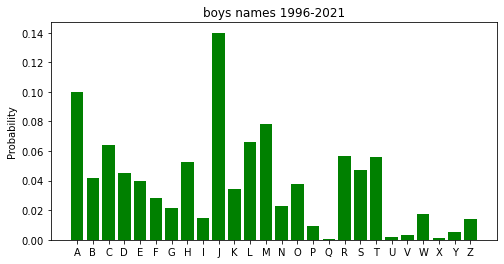
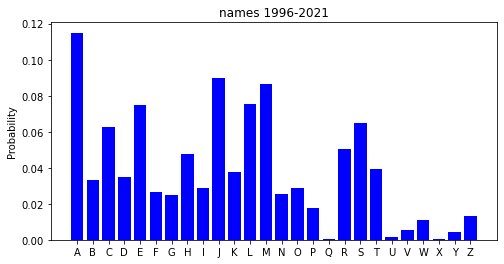
Before any calculations, I needed data to model the probability distribution of the first letters of names. I’ll call these First Letter Distributions (FLDs). Using UK census data I calculated some FLDs and details are below.
Click to read boring data details
I couldn’t find many comprehensive lists of names which included frequencies, the best I found was from the UK census data here. The census data is split by gender (assigned from birth) and by year from 1996 to 2021, which as of writing will include anyone from the age of 2-28. This isn’t perfect for the right age range for Lee Mack’s partners but it’ll do.
Resulting first letter distribution.
Here are the produced FLDs, red for girls, green for boys and blue for the unisex distribution.
Every scenario
The problem can be interpreted at least 4 ways, those being:
- With no choices, with a specific order
- With no choices, without a specific order
- With choices, and with a specific order
- With choices, and without a specific order
to produce an acronymic group of the letters ‘BERMUDA’, given the group size is seven.
A scenario with a specific order means we care about the sequence of when members join a group, without means we don’t care and allow any permutation.
A scenario with choice is one where you can select your next partner from a pool of N people at every stage—a scenario briefly mentioned in the video.
Calculations for these four scenarios follow, specifically for the word BERMUDA, using unisex FLD data from 1996-2021 as the FLD for each of Lee Mack’s partners names. Most code is omitted if you’re interest it’s available on this github repository.
Calculations here don’t consider the chance of Lee Mack having exactly exactly seven exes’, or in the general case the group being the exact length of word we’re interested in.
Scenario 1
This is a straightforward calculation, we multiply by the probabilities of each letter in BERMUDA. Which gives us the answer: \(5.751 \times 10^{-11}\). With this probability, we might expect roughly 0.4 people on earth to fulfil this scenario - it seems very unlikely that Lee Mack is of them.
Scenario 2
This scenario is the same as the previous, except we must account for every possible ordering. We can calculate this by multiplying the calculated probability from scenario 1 by the number of distinct permutations of the letters of the given word. The specific formula needed for this is the Multinomial coefficient formula:
\[\binom{n}{k_1,...,k_m} = \frac{n!}{k_1!.k_2!.....k_m!}\]where \(n\) is the total number of letters and \(k_1, ... k_{26}\) is the frequency of each letter in the word.
In this situation the multinomial coefficient is simple, as all letters in the word occur once. Therefore they can occur in \(7*6*…*1=7!=5040\) different ways, so we simply multiply the previous probability used in scenario 1 to obtain our answer of \(2.898 \times 10^{-7}\).
With this probability, we might expect around 2300 people on earth to fulfil scenario 2 - with this I still wouldn’t believe Lee Mack.
Scenario 3
In this scenario we must consider each stage, where our agent chooses the next person added to the group from \(k\) choices and there is a desired letter to select to satisfy the desired ordering. e.g the first letter ‘B’.
If we let \(B\) be the number of letter ‘B’s (or whatever letter is needed) obtained from this stage, it will follow the binomial distribution \(B \sim \text{Bin}(K, p_b)\) where k is available choices, \(p_b\) is the probability of the letter from the FLD.
At any stage we just need one person with a letter B, and the probability of that is \(P(B\ge 1)=1-P(B=0)=1-(1-p_b)^{k}\). We calculate the total probability by repeating for all letters in BERMUDA, multiplying each one together and the results for several values of K are in the table below.
| Choices | 2 | 4 | 6 | 8 | 10 | 15 | 20 | 50 | 100 | 1000 |
|---|---|---|---|---|---|---|---|---|---|---|
| Answer | 6.02e-9 | 5.19e-7 | 6.04e-6 | 3.12e-5 | 1.04e-4 | 7.52e-4 | 0.0026 | 0.0393 | 0.118 | 0.740 |
With these results, the scenario can become very much plausible - if you can accept that value of K and the absurd motivations of such an agent.
Scenario 4
This is the same as Scenario 3, except that at each stage, we have a choice of letters to pick from, since any ordering of the group will suffice. This means an agent can play according to many different strategies. We will focus on the optimal strategy, where an agent always picks the person whose first letter is the rarest among those still needed (e.g., prioritizing an Ursula over an Amy).
I solve this recursively using the function solution below. (Note that it assumes no duplicate letters, so it would need modification for the general case.)
def solution(state, k, fld, cur=1):
"""
condition_multiplier: probability that current branch is best one meaning no wanted letters produced from above branches.
branch_prob: Probability of one appearance of desired letter i.
cur: Probability of being at current node in this tree search.
"""
if all(x==1 for x in state):
return cur
condition_multiplier = 1
total = 0
for i in range(len(state)):
if state[i] == 0:
branch_prob = 1-pow(1-fld[i], k)
next_cur = cur*branch_prob*condition_multiplier
state[i]=1
total += solution(state, k, fld, next_cur)
state[i]=0
if k > 1:
condition_multiplier *= (1-branch_prob)
return total
# Calculating the values for Bermuda
values = list(range(1,11))+[15, 20, 30, 40, 50, 100, 500]
for k in values:
answer = solution([0 for _ in WORD], k, reversed(inprobs))
print(f"{k: 5d} {answer:.4g}")
This solution function traverses the tree of optimal choices in a depth first search, tracking the current probability at each point. The array \(\textbf{state}\) stores which letters have been obtained at the current node, \(\textbf{state}[i]\) is \(1\) if we have gotten a letter[i] at the current node. \(\textbf{fld}\) contains the FLD modified to contain only the letters we are interested in (u,b,d,r,e,m,a) and sorted in ascending order. In this situation \(\textbf{fld}=[0.00134, 0.0330,0.0346,0.0501,0.0747,0.0862,0.114]\). And \(\textbf{cur}\) stores the probability of the current node.
Here’s my best graphical explanation, using a simplified case of looking for a word ‘ABC’ with the probabilities of each letter being \([0.1, 0.2, 0.3]\)
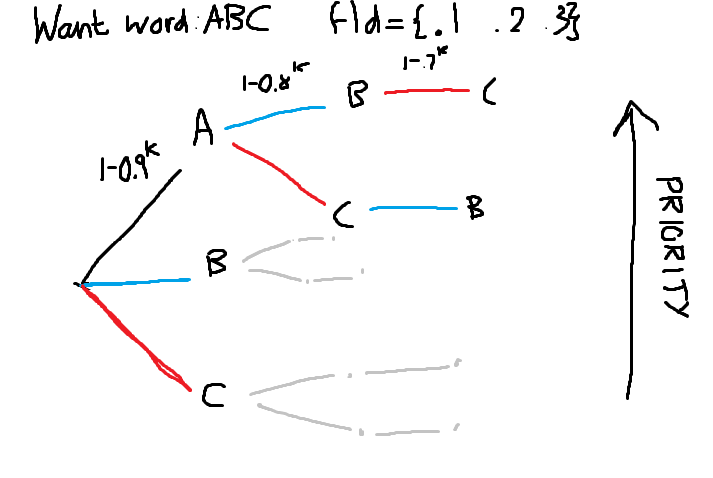
For example at the B node at state \([0, 1, 0]\) what I unhelpfully named \(\mathit{full\_ thing}\) is equal to the probability that no A’s were obtained and at least 1 B was obtained. This is equal to \(P(A=0)\times P(B\ge 1) = (1-0.1^{k}) \times (1-(1-0.2)^{k})\). We get the full answer by summing all leaf nodes, which all have states of \([1,1,1]\) .
The results I obtained are in the table below, I’ve also included an upper bound which assumes a uniform probability for all letters. Annoyingly, it is within an order of magnitude of the actual calculation. A learning point for next time: look for easy upper-bound solutions for silly statistical questions before spending a week on the exact answer! The upper bounds are calculated with this formula.
\[U = \prod_{i=0}^{6} \left(1 - \left(1 - \frac{7 - i}{26}\right)^k\right)\]| Choices | Prob | Upper bound |
|---|---|---|
| 1 | 2.898e-07 | 6.275e-7 |
| 2 | 1.525e-05 | 4.558e-5 |
| 3 | 0.000155 | 0.000451 |
| 4 | 0.0007026 | 0.002005 |
| 5 | 0.002063 | 0.00578 |
| 6 | 0.004632 | 0.0127 |
| 7 | 0.008683 | 0.0237 |
| 8 | 0.01432 | 0.0387 |
| 9 | 0.02149 | 0.0577 |
| 10 | 0.03003 | 0.0802 |
| 15 | 0.08467 | 0.223 |
| 20 | 0.142 | 0.374 |
| 30 | 0.2367 | 0.607 |
| 40 | 0.3114 | 0.752 |
| 50 | 0.3752 | 0.841 |
| 100 | 0.6109 | 0.980 |
| 500 | 0.9911 | 0.999 |
To conclude the results, scenario 1 seems impossible, scenario 2 seems near impossible, and scenario 3 seems plausible for (k>20) and scenario 4 for (k>10).
So if you have a strange obsession with the word bermuda and are a highly sought-after partner, rest assured it should be surprisingly simple to systematically select and secure your specifically named significant others, unless susceptible to statistical significance.
In the next post I’ll show more general code and compute the statistics for the most likely acronymic groups, for each scenario.
References
- WILTY clip: https://www.youtube.com/watch?v=sypQXXN57T8
- Census data: https://www.ons.gov.uk/peoplepopulationandcommunity/birthsdeathsandmarriages/livebirths/datasets/babynamesinenglandandwalesfrom1996
- Reference first letter distribution: https://themeaningofthename.com/traffic-and-name-statistics/names-first-letter-distribution/
- Multinomial theorem: https://en.wikipedia.org/wiki/Multinomial_theorem