Tags: stats, language, weird_questions 2nd Feb 2023
Acronymic Groups (Part 2)
This second post will look at the general case where we are looking at words beside BERMUDA, showing the code for that (where interesting) and looking at the results when we plug in a dictionary.
For an English wordlist I ended up using this word list, of about 50,000 words and which contains far less obscure words than other word-lists.
Results
With a word-list and the calculated FLDs we can calculate real probabilities for every word and every scenario, those being with and without order, and with and without choices. We begin by looking at Scenario 1.
I calculate the probabilities, written as prob, by simply going through each letter in a word, and multiplying by its probability in the given FLD.
Here are the top 20 most likely words, using the unisex FLD. The unfortunate result is that the most probable are boring 2 letter words.
word prob normalised
am 0.009912 0.099558
as 0.007465 0.086401
me 0.006445 0.080281
em 0.006445 0.080281
ms 0.005599 0.074825
ah 0.005459 0.073884
ha 0.005459 0.073884
at 0.004511 0.067167
mr 0.004327 0.065782
re 0.003752 0.061251
he 0.003550 0.059578
eh 0.003550 0.059578
an 0.002900 0.053854
im 0.002481 0.049808
be 0.002474 0.049737
pa 0.002036 0.045124
ne 0.001886 0.043427
so 0.001872 0.043268
is 0.001869 0.043226
eg 0.001860 0.043129
This ‘Normalised’ metric is not actually a normalised probability but is equal to \(\sqrt[n]{prob}\) which will give a sense of which words are most likely whilst allowing longer words to rank equal to shorter words.
Poisson: calculates the probability based on the assumption that the average number of exs is 5 using a poisson distribution, so this may represent a more realistic scenario than prob which suggest the probability of having 1 ex is the same as 5.
And if we sort by normalised it gets a tad bit more interesting.
both: | women: | men:
word prob normalised poisson | word prob normalised poisson | word prob normalised poisson
ala 9.974e-4 0.0999 1.400e-4 | ala 0.001435 0.1127 2.014e-4 | jam 1.089e-3 0.1028 1.528e-4
am 9.911e-3 0.0995 8.348e-4 | mama 0.000151 0.1108 2.652e-5 | ajar 7.907e-5 0.0943 1.387e-5
mama 9.824e-5 0.0995 1.723e-5 | am 0.012294 0.1108 1.035e-3 | raj 7.934e-4 0.0925 1.113e-4
lama 8.600e-5 0.0963 1.509e-5 | lama 0.000135 0.1078 2.376e-5 | jar 7.934e-4 0.0925 1.113e-4
jam 8.913e-4 0.0962 1.251e-4 | ease 0.000130 0.1067 2.282e-5 | am 7.779e-3 0.0882 6.552e-4
salaam 6.420e-7 0.0928 9.387e-8 | lea 0.001213 0.1066 1.702e-4 | mama 6.051e-5 0.0882 1.061e-5
mammal 6.393e-7 0.0928 9.348e-8 | ale 0.001213 0.1066 1.702e-4 | ala 6.591e-4 0.0870 9.253e-5
llama 6.490e-6 0.0917 1.138e-6 | salaam 0.000001 0.1064 2.126e-7 | jarl 5.265e-5 0.0851 9.238e-6
mamas 6.379e-6 0.0914 1.119e-6 | sea 0.001182 0.1057 1.658e-4 | jams 5.168e-5 0.0847 9.069e-6
lam 7.480e-4 0.0907 1.050e-4 | mamas 0.000012 0.1044 2.185e-6 | lama 5.145e-5 0.0846 9.028e-6
alas 6.477e-5 0.0897 1.136e-5 | alas 0.000118 0.1042 2.075e-5 | rajah 4.155e-6 0.0838 7.290e-7
lamas 5.584e-6 0.0890 9.799e-7 | as 0.010734 0.1036 9.041e-4 | jab 5.814e-4 0.0834 8.162e-5
mammals 4.151e-8 0.0881 4.336e-9 | male 0.000114 0.1034 2.008e-5 | mammal 3.134e-7 0.0824 4.583e-8
ajar 5.964e-5 0.0878 1.046e-5 | meal 0.000114 0.1034 2.008e-5 | jamb 4.538e-5 0.0820 7.963e-6
jams 5.788e-5 0.0872 1.015e-5 | lame 0.000114 0.1034 2.008e-5 | mara 4.409e-5 0.0814 7.736e-6
alabama 3.761e-8 0.0869 3.928e-9 | mammal 0.000001 0.1031 1.764e-7 | llama 3.414e-6 0.0806 5.991e-7
mara 5.718e-5 0.0869 1.003e-5 | seam 0.000112 0.1027 1.957e-5 | aha 5.219e-4 0.0805 7.326e-5
all 6.548e-4 0.0868 9.192e-5 | same 0.000112 0.1027 1.957e-5 | lam 5.162e-4 0.0802 7.246e-5
mall 5.646e-5 0.0866 9.907e-6 | llama 0.000011 0.1027 2.010e-6 | alabama 2.129e-8 0.0801 2.224e-9
llamas 4.215e-7 0.0865 6.163e-8 | lamas 0.000011 0.1022 1.958e-6 | cam 4.995e-4 0.0793 7.012e-5
Most probable words
The following two tables show the top 20 most probable words grouped by word size. These values have been calculated by the combined unisex FLDs. Gendered results are in the next section. Each table also includes total_prob which is the total summed probabilities over all words of word length K. N is the total number of words we have of length K. in the vocabulary.
2-word prob 3-word prob 4-word prob 5-word prob
am 0.009912 ala 0.000997 mama 0.000098 llama 0.000006
as 0.007465 jam 0.000891 lama 0.000086 mamas 0.000006
me 0.006445 lam 0.000748 alas 0.000065 lamas 0.000006
em 0.006445 all 0.000655 ajar 0.000060 lemma 0.000005
ms 0.005599 lea 0.000649 jams 0.000058 amass 0.000005
ha 0.005459 ale 0.000649 mara 0.000057 james 0.000004
ah 0.005459 sam 0.000644 mall 0.000056 alarm 0.000004
at 0.004511 mas 0.000644 lame 0.000056 salsa 0.000004
mr 0.004327 aha 0.000628 male 0.000056 areal 0.000004
re 0.003752 cam 0.000623 meal 0.000056 small 0.000004
eh 0.003550 mac 0.000623 area 0.000050 malls 0.000004
he 0.003550 las 0.000563 elal 0.000049 meals 0.000004
an 0.002900 sea 0.000558 slam 0.000049 males 0.000004
im 0.002481 ace 0.000540 alms 0.000049 salem 0.000004
be 0.002474 raj 0.000519 seam 0.000048 camel 0.000004
pa 0.002036 jar 0.000519 same 0.000048 madam 0.000003
ne 0.001886 ram 0.000497 clam 0.000047 malta 0.000003
so 0.001872 arm 0.000497 calm 0.000047 mamba 0.000003
is 0.001869 mar 0.000497 mace 0.000047 areas 0.000003
eg 0.001860 elm 0.000486 came 0.000047 slams 0.000003
total_prob = 0.1036 total_prob = 0.05914 total_prob = 0.01355 total_prob = 0.001317
N = 47 N = 589 N = 2294 N = 4266
6-word prob 7-word prob 8-word prob
salaam 6.420e-7 mammals 4.151e-8 mammalia 2.114e-9
mammal 6.393e-7 alabama 3.761e-8 caracals 1.475e-9
llamas 4.215e-7 marsala 3.222e-8 amalgams 1.377e-9
lemmas 3.130e-7 mascara 2.682e-8 caramels 1.316e-9
alaska 2.810e-7 amasses 2.332e-8 seamless 1.144e-9
alarms 2.802e-7 caracal 2.271e-8 massacre 1.132e-9
allele 2.761e-7 jamaica 2.129e-8 malarial 1.077e-9
camera 2.685e-7 amalgam 2.121e-8 alacarte 1.060e-9
madame 2.547e-7 mahatma 2.104e-8 almanacs 1.017e-9
smalls 2.380e-7 caramel 2.027e-8 massless 9.943e-10
sahara 2.351e-7 cascara 1.954e-8 sarcasms 9.839e-10
sesame 2.335e-7 alleles 1.793e-8 saleable 9.040e-10
camels 2.281e-7 measles 1.762e-8 escalate 8.924e-10
armada 2.280e-7 cameras 1.744e-8 callable 8.831e-10
madams 2.212e-7 almanac 1.567e-8 marshals 8.642e-10
jackal 2.127e-7 sarcasm 1.515e-8 teammate 8.454e-10
mambas 2.111e-7 armadas 1.480e-8 carcases 8.253e-10
pajama 2.086e-7 malaria 1.427e-8 escalade 7.887e-10
leases 2.044e-7 lacteal 1.387e-8 releases 7.670e-10
easels 2.044e-7 academe 1.387e-8 scalable 7.598e-10
total_prob = 0.0001057 total_prob = 6.781e-6 total_prob = 3.3527e-7
N = 6936 N = 9203 N = 9396
Boy results and girl results
Gendered results can be found here: Gendered results
Scenario 2
To calculate the probabilities, we calculate the number of permutations of the letter in the word using the multinomial coefficient formula for each word and multiply that by the probabilities in Scenario 1. The result tables can be found here: Gendered results
Scenario 3
The following code solves scenario 3, which can be thought of scenario 1 - except at each stage we must calculate the probability of not getting letter \(L\) from \(K\) choices which we do with a simple binomial.
def scenario3(fld, word, k):
word = word.upper()
prob = 1
for letter in word:
p =fld[ord(letter)-65]
prob *= 1-pow(1-p, k)
return prob
values = list(range(1,11))+[15, 20, 30, 40, 50, 100, 500]
fld = [1/26 for _ in range(26)]
word = "bermuda"
for k in values:
answer = scenario3(unisex_fld, word, k)
print(f"{k: 5d} {answer:.4g}")
It seems for most values of K, the most probable values are roughly all the same up to some large value of K value, and so I will omit dumping too much data here. You can confirm that by looking at the results for word length 5 results, that shows the consistent ordering. And when K=1 (a single choice per letter) this reduces to scenario 1 - so you can refer to the data there to see what is most likely for any word, and any small K value you might be interested in.
Scenario 4
The code use here is similar to the version from the previous post but generalised to work for any word, and it has been optimised to use memoisation.
@lru_cache(maxsize=None)
def solution(state, k, fld):
current_state = list(state)
if all(x == 0 for x in current_state):
return 1.0
total = 0
cur = 1
for i in range(len(current_state)):
if current_state[i] > 0:
branch_prob = 1-pow(1-fld[i], k)
current_state[i] -= 1
total += cur * branch_prob * solution(tuple(current_state), k, fld)
current_state[i] += 1
if k > 1:
cur *= (1-branch_prob)
return total
# Acronym group case 4 generic case
def presolution(fld, word, k):
word = word.upper()
letter_freq = [0 for _ in range(26)]
for i in word:
letter_freq[ord(i)-65] += 1
sorted_freq = sorted(zip(letter_freq, fld), key=lambda x: x[1] )
sorted_state = [x[0] for x in sorted_freq]
sorted_fld = sorted(fld)
return solution(sorted_state, k, sorted_fld)
values = list(range(1,11))+[15, 20, 30, 40, 50, 100, 500]
unisex_fld = [0.11496, 0.03309, 0.06283, 0.03468, 0.07475, 0.02670, 0.02488, 0.04748, 0.02877, 0.08992, 0.03774, 0.07547, 0.08621, 0.02522, 0.02882, 0.01771, 0.00054, 0.05018, 0.06493, 0.03924, 0.00134, 0.00536, 0.01096, 0.00071, 0.00419, 0.01318]
word = "bermuda"
for k in values:
answer = presolution(unisex_fld, word, k)
print(f"{k: 5d} {answer:.4g}")
Using the code, with some changes I have done a search of the most probable words over K = [2,5,10] and word lengths from 3 to 9. The results are here. Interesting enough the most probable 5-letter word, using the same FLD is in fact my name: James.
One aspect not yet addressed (but briefly mentioned above) is the conditional probability distribution of group sizes ( the chance of Lee Mack having exactly seven exes’) which would be actually relevant if trying to figure out if Lee Mack’ is lying. However I will leave this as an exercise to the reader.
Addendum
- Original link of wordlist: http://www.mieliestronk.com/wordlist.html
- Copy of the wordlist on my github.
- Full code
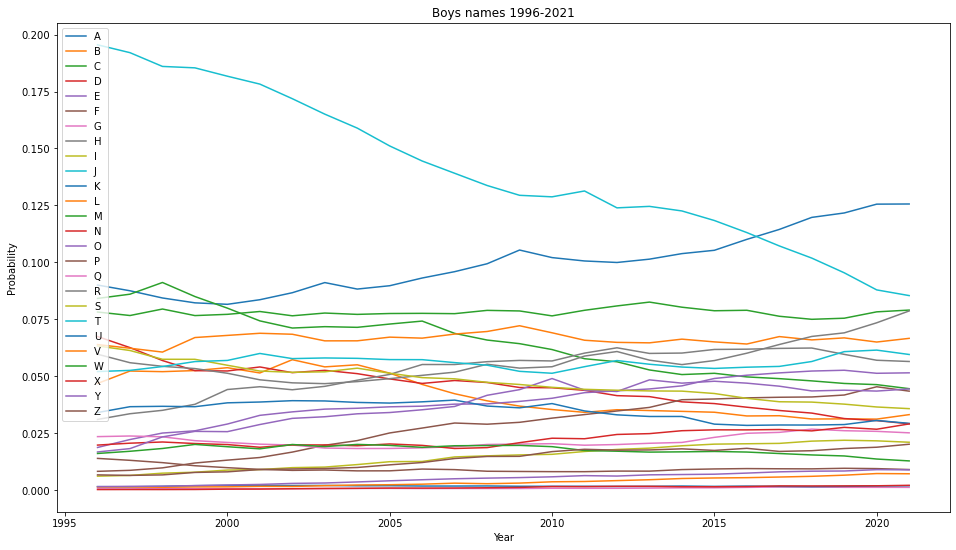
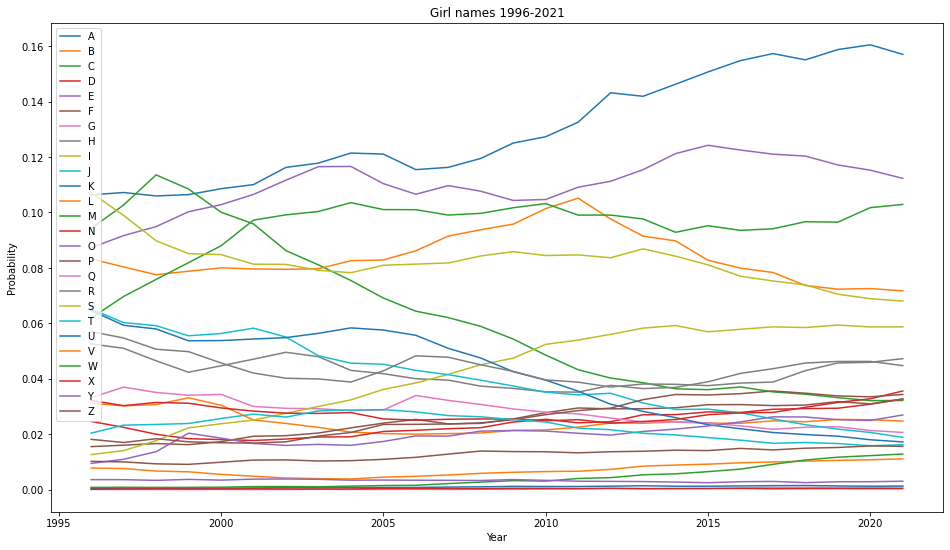
Here are the changes of the FLDs for boy and girl names from the year 1996-2021, using the census data.